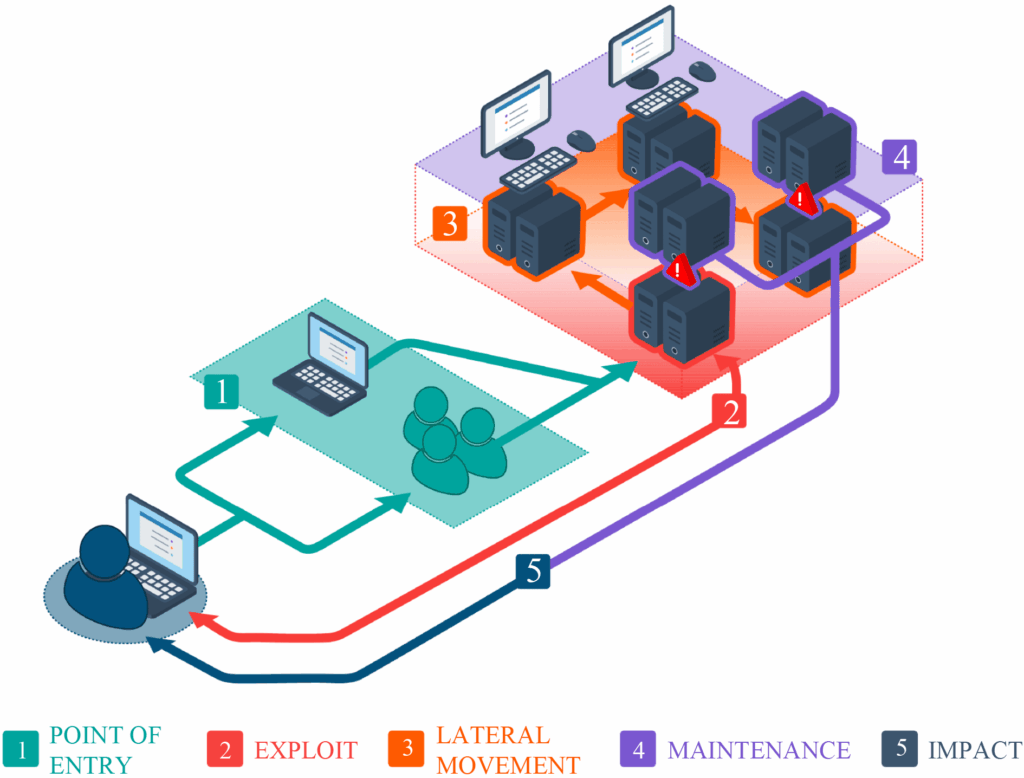
The MEDIATE cybersecurity framework’s Decision Support System (DSS) is designed to improve cyber defense strategies within IoT, edge, and cloud ecosystems by leveraging Multi-Objective Reinforcement Learning (MORL). In many security scenarios, optimizing for a single outcome falls short. Cyber defense needs to balance multiple goals, like effectiveness, minimal operational disruption and cost-efficiency. MORL enables the system to evaluate and accommodate multiple, often conflicting objectives simultaneously, producing a range of Pareto-optimal strategies rather than converging on a single solution.
MORL extends traditional Reinforcement Learning (RL) by framing decision-making challenges within a Multi-Objective Markov Decision Process (MOMDP). This approach is especially valuable in cybersecurity, where diverse and dynamic threats demand adaptive and nuanced responses. By integrating MORL, the DSS can continuously adjust its defensive posture in real time, dynamically weighing factors such as threat severity, resource allocation, and operational impact. This capability is critical in an environment where cyberattacks are both increasingly sophisticated and unpredictable.
To optimize learning and operational performance, the DSS employs deep reinforcement learning techniques, such as value-based, policy-based, or actor-critic algorithms, each adapted to accommodate multiple reward signals. By doing so, the DSS can scale to high-dimensional state spaces and complex operational environments, ensuring that the selected defense strategies are both robust and practical. In addition, the system is designed with a focus on error mitigation. Cybersecurity applications demand high reliability, and the DSS incorporates mechanisms such as robust reward shaping, conservative exploration strategies, and confidence-based policy selection to manage uncertainty and prevent the deployment of suboptimal or unsafe actions.
The flexibility of MORL lies in its ability to use either scalarization-based or Pareto-based methods. Scalarization simplifies multi-objective problems by converting them into a single reward function, albeit with the drawback of requiring predefined weights. Alternatively, Pareto-based approaches maintain multiple policies to explore the spectrum of optimal trade-offs, providing a more adaptable but computationally demanding solution. This flexibility lets the DSS adapt to changing priorities and contexts.
The MEDIATE framework’s DSS harnesses the power of MORL and deep reinforcement learning to deliver an adaptive, reliable, and efficient cyber defense solution. By managing trade-offs between competing objectives and incorporating robust error mitigation strategies, this approach supports real-time, data-driven decisions in complex and evolving threats environments.